在测试时延的时候,对c++提供的时钟函数进行了些研究和考察,下面是相关的记录。
Modern C++中多态的实现方法(union,virtual,variant)
最近做服务器的项目的时候,在优化自己的架构,抽象出了一个适配器层,服务器将借由这个适配器的抽象来到达上层的用户接受消息层。而适配器层所负责的就是建立连接,不管是tcp的epoll模式连接,还是rdma编程模式下的建立连接,我们都希望借助抽象出适配器的子类派生出来实现,在这样的结构下,一是对代码做到了很好的简化作用,二是可以做到以后更深层次的扩容,架构的可扩展性比较好,以后也可以接入如kafka这样的消息中间件做异步的消息转发,提高服务器的程序吞吐量,三也是方便我写测试代码。
所以说这层抽象是很重要的。并且要实现这样的抽象类和派生类,我们就需要用到c++的多态。而我其实也是在学习modern C++的过程中了解到C++17引入了variant,也是学习了一下相关的知识,在这次博客我会记录下c++这三种不同的多态实现方式union,virtual和variant。在这里我也写一下对这三种多态方式做出的研究吧。
首先是最熟悉的virtual,C++编译器实现 “virtual” 的机制是通过在类的虚函数表(vtable)中存储虚函数的地址,并在对象中添加一个指向虚函数表的指针。当一个对象调用一个虚函数时,编译器会根据对象的类型和虚函数在虚函数表中的位置,找到对应的虚函数指针,然后调用该函数的实现代码。由于虚函数表是在编译期间创建的,因此可以在运行时根据对象的实际类型动态地调用相应的虚函数,实现多态性。
下面是一个简单的c++ virtual实现的多态示例。
1 |
|
可以看到,通过c++ virtual实现的多态代码非常的直观,但是这也毫无疑问带来了一定的缺点,主要的缺点就在于,纯虚函数是不能内联的,这是因为内联函数在编译时会直接将函数的代码插入到调用处,从而避免了函数调用的开销。但对于虚函数来说,由于它在运行时才确定调用的实际实现,即使你代码后已经对他进行了指针类型的强制转化,仍旧不能在编译时确定具体的函数实现,导致了他在运行时会去寻找相应的代码,从而影响程序的性能。因为希望做的是一个低延迟的交易系统,性能事实上是十分关键的因素。
第二种写法为类似c语言的写法,我们在c语言中实现多态的时候,就会使用union来实现,就像c版本tiger编译示例代码中所实现的那样,他的好处是代码程序的性能很高,但缺点就是程序的易读性不高,并且子类增加维护页非常麻烦,union无法自动处理构造和析构等逻辑,不能保证类型安全。
由此,C++17提出了std::variant,这是一种类似于联合体(union)的数据类型,它可以在同一块内存空间中存储多个不同的类型,但每次只能使用其中的一个成员。与联合体不同的是,std::variant 提供了安全和类型安全的访问方式,这是因为访问 std::variant 的成员是通过模板参数和类型匹配实现的,而不是像联合体一样使用显式的成员名称。同时,std::variant 还提供了许多方便的成员函数,如 std::get 和 std::visit 等,可以更方便地访问其中的成员。
C++ variant实现
1 |
|
从C++17发布出来的信息来看,他是能做到虚函数内联的。使用 std::variant 实现多态时,由于它是一个模板,编译器可以在编译期确定各个类型的大小和布局,因此可以使用内联方式实现,避免了虚函数和虚表的开销。
Socketnetwork
在做暑期项目的过程中有许多相关的计算机网络协议至网络ip等知识,在做项目的同时我也有意去查找学习相关的计算机网络知识,在这篇博客也是记录一下相应的学习。此外本篇记录并不希望像别的博客一样是单纯的知识的罗列,计算机是一个整体,从socket的网络连接到网络协议都是密不可分的,我希望在这篇博客中能够将系统的知识到计算机网络的知识都串联起来,关注点更在于一个整体的流程框架理解,而非一个个孤立的点,因此本文并不会着重于讲解计算机网络各种各样的细节或是不同的转换类型,协议、报文的具体细节,解析方式等,我认为这才是较为优雅的能够形成整体认知的学习方式。
从计算机硬件到计算机系统
回到计算机系统,CSAPP中第十一章的11-2图片其实已经很好地展示了计算机系统中相应的网络配置是处于一个什么位置,DMA(Direct Message Access)事实上指代的就是硬件技术,直接从网络口传输到了主存(DRAM)当中。
CSAPP的网络连接中介绍了最为基本的Socket连接,那他的运行机制是什么呢?对于网络编程,在CSAPP的学习过程中,只了解到了listen,accept,write()的接口,CSAPP中也给出了一台主机和另一台主机Socket的流程图,如下图所示,就是一个创建了Socket连接并且另一台监听的过程。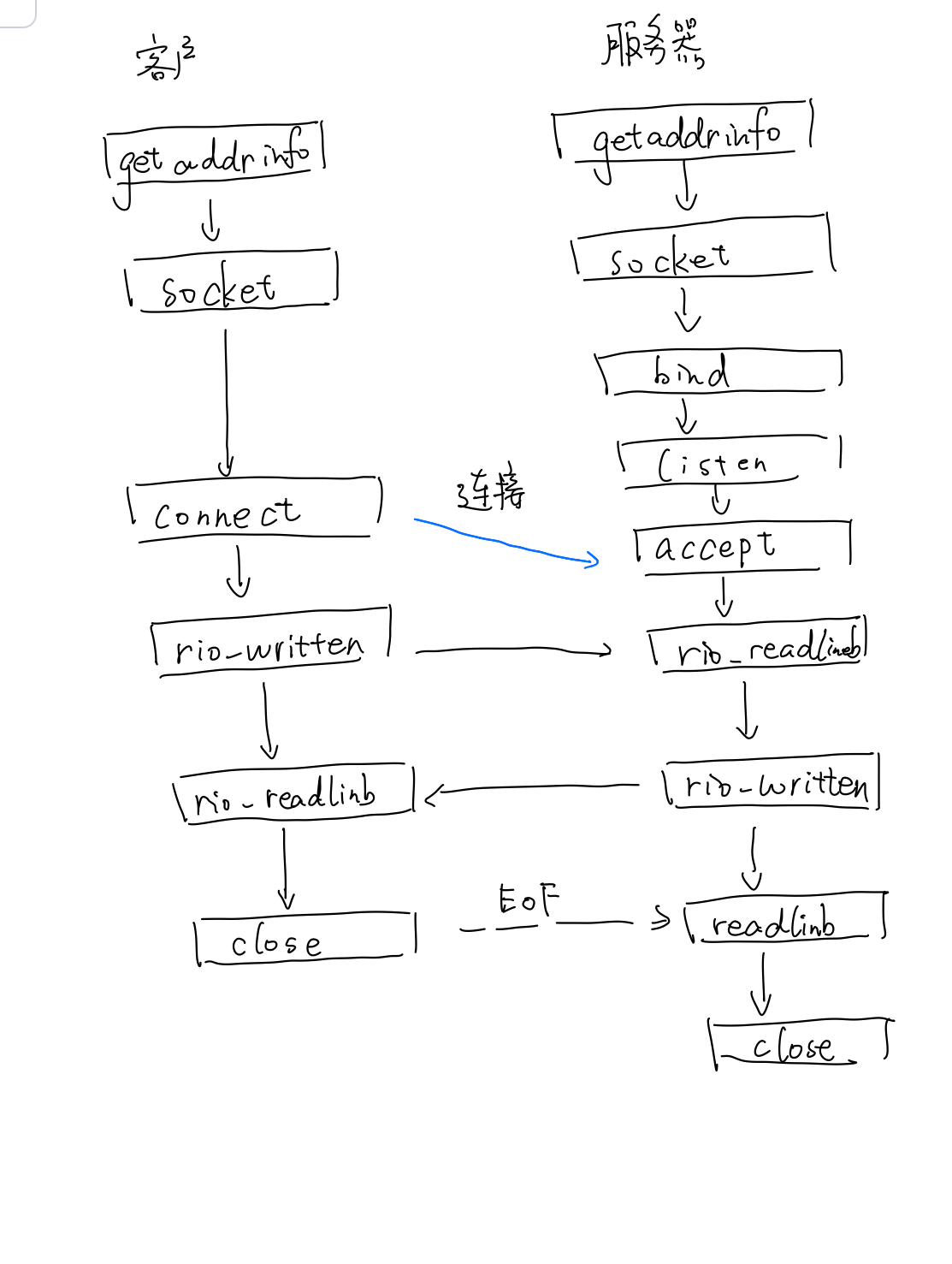
那我们进一步深入思考,建立连接之后要发送数据,相应的数据是怎么通过建立的socket连接发送到另一台电脑的呢?那他发送数据的流程是怎么样的呢?
我们以TCP/IP五层模型为例,画了下面一张图,可以得到结论,建立socket后发送数据的过程就是往原先的字符串添加不同的信息以便收到时能解构为完整的信息,不同层级的封装,本质就是不停地在字符串前面添加新的字符。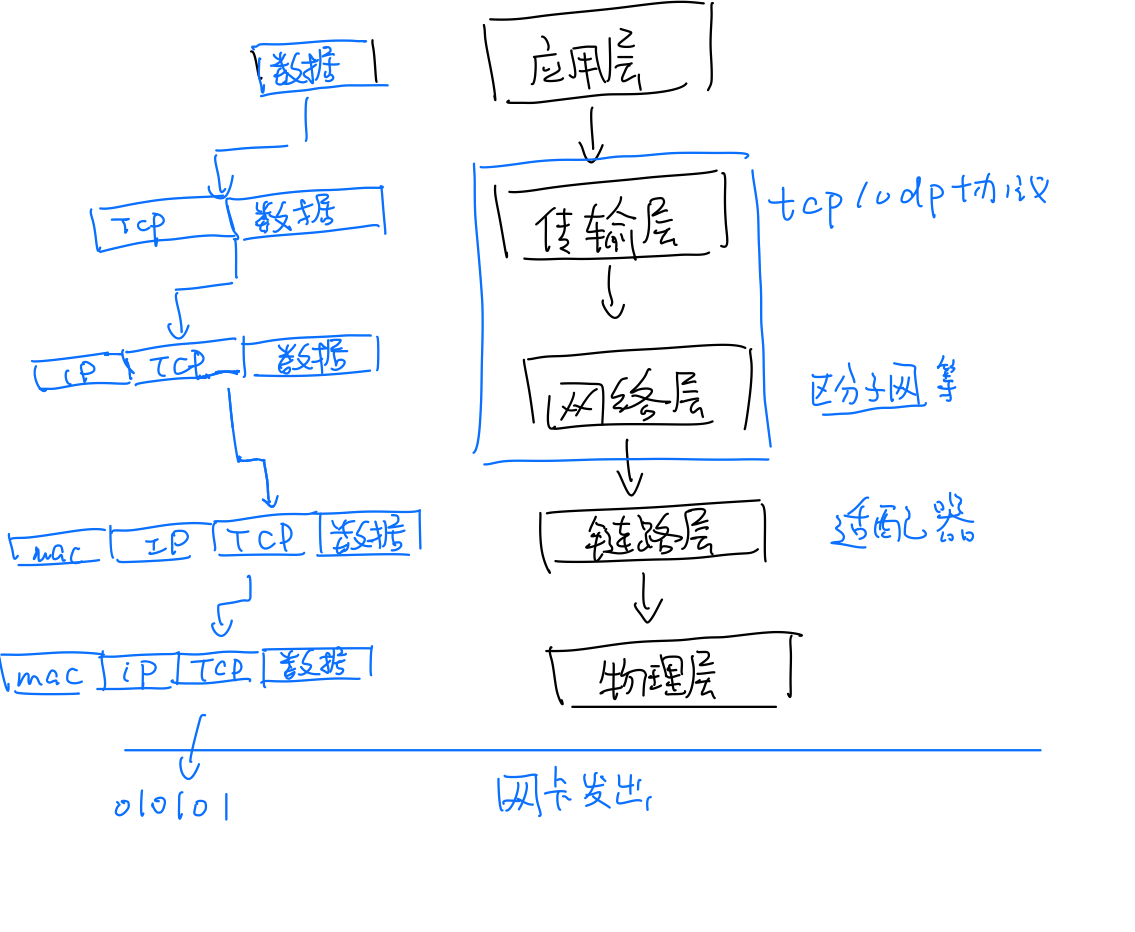
这只是一次发送需要经历的流程,而作为系统一方,他需要对不同时间戳,不同程序连接的Socket所传递的字符串都做出统一的管理,那么linux内部是如何管理这些字符串的呢?
我阅读了linux0.11的源码,他使用的是sk_buff结构体存储一个字符串的相应信息,并且通过双向链表来维护他。在下面我写了linux代码的关键部分。
1 | struct sk_buff { |
大抵结构如上所示,因此每收到一个socket的字符串,系统都会保存起来,而保存的方式就是建立一个缓冲区,分配相应的内存块,并且设立报文的头指针和尾指针。然后在添加相应报头信息的时候移动头指针和尾指针,来扩大缓冲区存储的区域。
这也是对socket连接传输信息过程中对Data Buffer的开销的具体解释,我们原本粗浅的理解为将字符串用户进程复制到内核进程的缓冲区,再通过相应的操作传出去。在阅读了相应的知识和源码后,应该就能理解为什么要这么做。os缓冲区的建立是为了进一步添加不同的层级协议报文,这也会不可避免地带来多余的开销。
也因此,Socket其实并不是一个协议,而是为了方便使用TCP或UDP而抽象出来的一层,是位于应用层和传输控制层之间的一组接口。
PS:项目中webrtc创建的stun/turn服务器原理
本次项目运用到了基于websocket协议的视频传输以及消息传输。
而所谓的websocket,webrtc,http,这些都是基于TCP/IP上层的进一步封装。
视频通讯基于webrtc,webrtc本质上是peer-to-peer的socket连接,传送相应的视频信息,stun服务器的作用是将获取该主机真实的ip地址。如果没有对应局域网自己的ip地址。而turn服务器的作用就是当两者无法进行p2p连接时,作为中继站的服务器。
再到计算机网络
……待更
6.830项目记录
Database|6.830 lab1
为了对数据库系统有更深层次的理解,尝试在暑期间做了6.830的Lab。
项目展图
本项目主要实现了数据库系统,包括了存储系统Storage,查询Query框架,查询的优化器Optimizer,索引的查询B+-tree实现等。整个项目的框架大致会随着项目的逐渐深入给出。
环境配置
ant环境配置下载官网上的在ant build,按照README中的教程执行即可。
Tuple/Tuple Desc
Tuple和TupleDesc类较为简单,注意好已经提供了Field的字段封装。TupleDesc需要type和fieldname两个属性,一个用来标明数据的属性,一个用来记录数据的,将其这两属性包裹为TdItem静态类,使用ArrayList保存即可。Tuple中包含TupleDesc,RecordId以及ArrayList<Field>,qizh其中RecordId在前几个Lab并没有作用,是在后期
1 | private TupleDesc tupleDesc; |
Buffer Pool
buffer pool是一个缓冲存储区,就是为了能够更快访问table所设立的区域
以Page作为基本单位。使用CocurrentHashMap来进行维护。
Page
在书写的过程中可以发现,SimpleDb中实现的相应的Page和大二下写过的Lsm-tree的写法非常类似,如果做类比的话BufferPool缓冲区就类似sst_buf,而Page就类似于SsTable的写法。也就是说比起当时LSM-tree的实现,SimpleDb在页的层级进行分割,对效率有了更大的提高,减少了IO操作。
HeapFile HeapPage
在设计db的过程中,最为重要的还是Dbfile和page都是一个抽象接口,可以Dbfile是一个table在硬盘的存储接口,而一个Dbfile。而在读取的时候以Page为单位来读取,pages来存储相应的Tuples。
每个Page的结构如下,
1 | final HeapPageId pid; |
page.getId().pageno()从对应Dbfile读取的起始偏移量Dbfile和Table的关系为一个Table对应的是一个Dbfile。Dbfile和Page有不同的实现方式,这也是数据io的主要优化点,lab1中实现的是最为基础的HeapFile和HeapPage
RecordId
RecordId是Tuple中包含的一个元素,他的目的是为了在添加以及删除Tuple确定Tuple所在的页位置以及页中的位置,因此包含两个元素PageId以及TupleNumber,通过这两个成员来实现Database对于Tuple的删除和添加操作。
Database|6.830 lab2
Project
关系代数投影
算法是编写的新的TupleDesc来做投影,子操作元素OpIterator child,Project利用新的TupleDesc和子操作的fetchNext来形成新的Tuple
Filter
Filter中使用Predicate进行Tuple判断是否符合条件,不符合条件则在fetchNext中跳过,和Project的逻辑类似。
Join
笔者在此实现的Join方式简单的simple nest join,也就是循环嵌套联结,通过二层嵌套来进行实现表和表的连接。事实上还有不同的实现方式,有
Agg
实现了IntegerAggregator以及StringAggregator。
具体思路是通过给定的gbfield将Tuple的gbfield位相同的合在一起,调用mergeTupleIntoGroup函数添加入组,通过op来相应对每个group进行聚合结果进行计算。其中IntegerAggregator都是对Intfield字段符的聚合,而StringAggregator是对StringField字符段的聚合,聚合操作只有COUNT。
笔者算法上采用HashMap存储相同的gbField和聚合结果的对应关系,IntAggregator中由于需要实现AVG聚合操作,因此既要相应的结果val,又需要相应的计数cnt,因此建立两个HashMap
1 | if(value){ |
Add and Delete
Add
加入Tuple的思路是先在HeapPage中寻找empty slot,如果有则在HeapPage的list中加入Tuple,同时修改该Tuple的RecordId;如果HeapFile内所有HeapPage都没有empty slot,则调用emptyPage创建新的HeapPage。
需要注意的是,所有的HeapFile中所有的getPage都需要调用BufferPool的getPage()方法,来获取相应的Page,原因一是通过BufferPool获取Page是可能可以减少磁盘IO操作的,二是最关键的,也是我做到Lab4才发现的,只有在这里的insertTuple和DeleteTuple中调用的是BufferPool中的getPage()方法,读和写的事务才能统一被管理,都在事务ACID协议的管辖范围内
Delete
Page Eviction
Flush Page
使用CocurrentHashMap中value的迭代器,将所有脏页写入磁盘
1 | public synchronized void flushAllPages() throws IOException { |
LRU缓存,实现方式类似Leetcode.146
将原先维护的CocurrentHashMap改为链表+HashMap的LRUCache类来进行维护。双链表是为了将调用的页插入队首,并且将队尾的页去除。
PS:笔者出于练手的目的造了LRUCache的轮子,事实上Java有自己的类似实现LinkedHashMap
Template Summary
完成Lab1以及Lab2后,Database基本的存储框架和增删查询的框架已经搭建完成,对于数据库的大抵架构也有所熟悉,我画了一张草图,来表示Database的大致结构。
Database|6.830 Lab3
Lab3主要是查询的优化,对查询语句
Lab3的Optimizer架构如下图所示,可以看到
而Optimizer中干的是两件事情:
- 第一阶段:收集表的统计信息,有了统计信息才可以进行,也就是Ex1,2做的是
- 第二阶段:根据统计信息进行估计,找出最优的执行方案。
通过创建直方图来解决filter selectivity estimation
估计相应的
TableStat.Java
TableStat主要是用来统计表中的信息,使用实现的IntHisgram对进行相应的实现。TableStat通过ConcurrentMap存储了表的名称和表的对应的关系。
算法思路如下:调用LAB2实现的SeqScan遍历,通过第一次遍历构建Field相应的Histogram,如果是IntField类则计算他的最大值和最小值,如果是StringField类则创建StringHistogram。
随后SeqScan.rewind(),进行第二次遍历,TableStat中实现以下3个Estimate:
estimateSelectivityestimateScanCostestimateTableCardinality
计算这些代码都是基于1
2joincost(t1 join t2) = scancost(t1) + ntups(t1) x scancost(t2) //IO cost
+ ntups(t1) x ntups(t2) //CPU costSeqScan来进行相对应的书写基数估计
Cardinality是指表中唯一值的行数,即是选择出来的行中该字段符应当不重复,对于有唯一约束的列,“基数”等于表的总行数。而选择性指的(Selectivity)的意思就是字段可取值相对于总行数的比值,公式如下:选择性 = 基数 / 总行数 * 100%
Join优化
根据相应的知识查询抗压发现,Join优化有两种,也就是先Filter再Join,会相应减少Cpu的操作
并且JoinOptimizer会相应的computeCostAndCardOfSubplan返回了CostCard
Database|6.830 Lab4
Transacation遵守ACID原则,ACID实现的前提是严格两阶段封锁协议(Strict two-phase locking)
两阶段封锁协议将事务分为两个阶段:
- 增长阶段:事务可以获得锁,但不能释放锁,锁的数量单调不减。
- 缩减阶段:事务可以释放锁,但不能获得新锁。锁的数量单调不增。
共享锁(Shared lock)以及排他锁(Exclusive lock)的区别和联系。
注意的是,一个事务t可能会多次访问同一个Page,而他说是锁实现使用类的等待获取来做到的,类似于读写锁。
下面有一张思维导图,很好地阐述了PageLock的工作逻辑
基于这张思维导图开始写PageLock页级别的锁和LockManager类来对BufferPool中的锁进行统一管理。
PageLock实现
首先使用枚举类型指定PageLock的两个类型EXCLUSIVE和SHARED,并且按照上面的思维图对应PageId的Page
Database|6.830 Lab5
未完待续……
Observability搭建
Observability
配置Prometheus
- 在Spring Boot中(pom.xml)引入依赖
1 | <dependencies> |
- 在application.properties中进行配置
1 | # Prometheus configuration |
- 在BackendApplication(主进程)中加入代码
1 | @Bean |
更改Prometheus目录下的Prometheus.yml, 在最后一行之后加入代码
这代表Prometheus会抓取该接口的数据(这正是我们Spring Boot中输出的信息)
1 | - job_name: 'springboot_prometheus' |
- 双击prometheus.exe运行,cheers! :beers:
- 登录localhost:9090,进入Prometheus UI界面
配置Grafana
- 在这里下载Windows版Grafana(Binaries版本)
- 下载之后解压到你要存放的文件夹中
- 运行bin目录下的grafana-server.exe
- 在conf文件夹下复制sample.ini文件,重命名为custom.ini,将http_port行取消注释(ini文件中 ‘;’ 即为注释,我们将 ‘;’ 删掉),将端口号改为你想要的端口号
- 进入localhost:${http_port}, 初始账户密码均为admin,登陆后按照指引修改密码
- 配置数据源,我们选择Prometheus,将URL补全为localhost:9090,DashBoard中import
Prometheus 2.0 Stats和Grafana metrics,点击Save & test,即可配置成功(前提是已经打开了Prometheus) - 之后我们在DashBoard中即可看到图表