在做暑期项目的过程中有许多相关的计算机网络协议至网络ip等知识,在做项目的同时我也有意去查找学习相关的计算机网络知识,在这篇博客也是记录一下相应的学习。此外本篇记录并不希望像别的博客一样是单纯的知识的罗列,计算机是一个整体,从socket的网络连接到网络协议都是密不可分的,我希望在这篇博客中能够将系统的知识到计算机网络的知识都串联起来,关注点更在于一个整体的流程框架理解,而非一个个孤立的点,因此本文并不会着重于讲解计算机网络各种各样的细节或是不同的转换类型,协议、报文的具体细节,解析方式等,我认为这才是较为优雅的能够形成整体认知的学习方式。
从计算机硬件到计算机系统
回到计算机系统,CSAPP中第十一章的11-2图片其实已经很好地展示了计算机系统中相应的网络配置是处于一个什么位置,DMA(Direct Message Access)事实上指代的就是硬件技术,直接从网络口传输到了主存(DRAM)当中。
CSAPP的网络连接中介绍了最为基本的Socket连接,那他的运行机制是什么呢?对于网络编程,在CSAPP的学习过程中,只了解到了listen,accept,write()的接口,CSAPP中也给出了一台主机和另一台主机Socket的流程图,如下图所示,就是一个创建了Socket连接并且另一台监听的过程。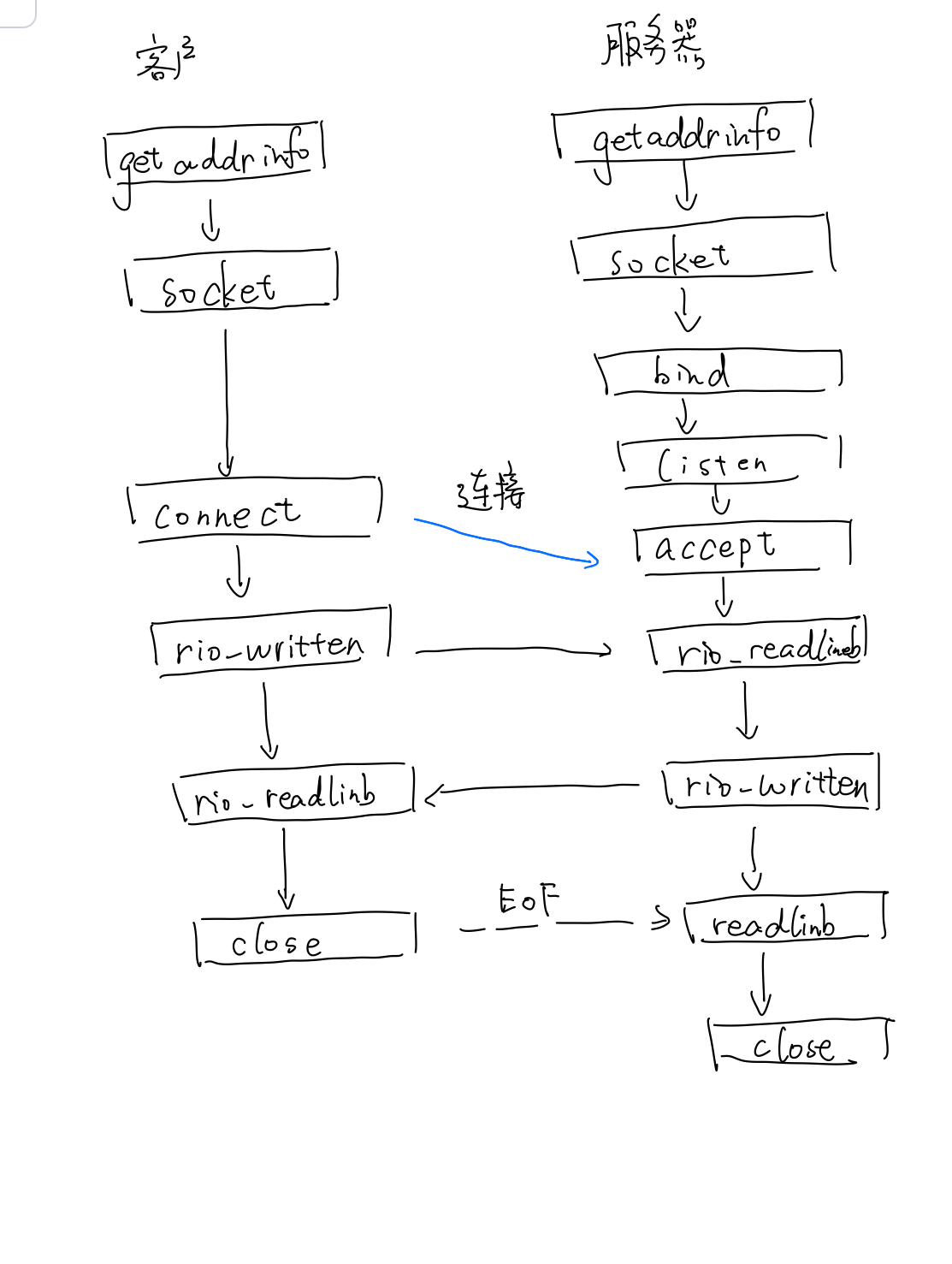
那我们进一步深入思考,建立连接之后要发送数据,相应的数据是怎么通过建立的socket连接发送到另一台电脑的呢?那他发送数据的流程是怎么样的呢?
我们以TCP/IP五层模型为例,画了下面一张图,可以得到结论,建立socket后发送数据的过程就是往原先的字符串添加不同的信息以便收到时能解构为完整的信息,不同层级的封装,本质就是不停地在字符串前面添加新的字符。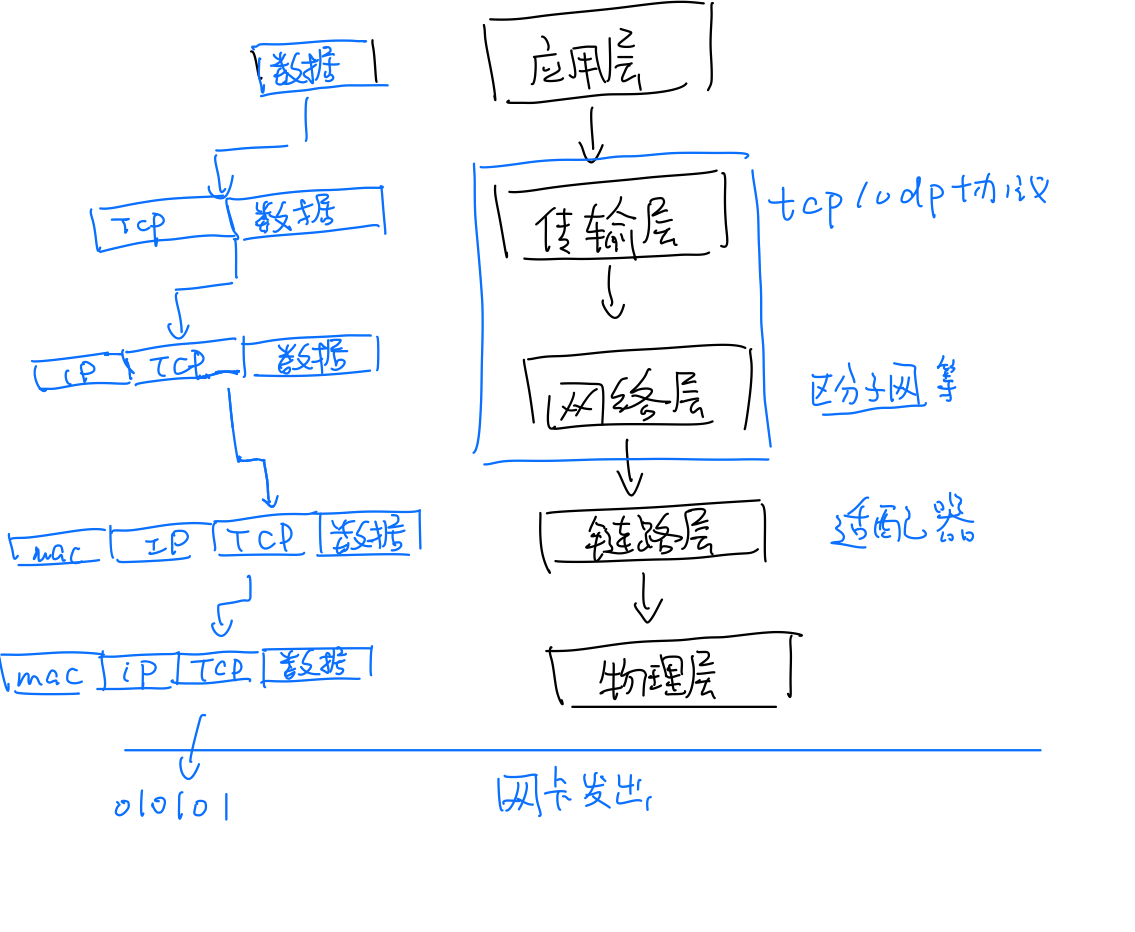
这只是一次发送需要经历的流程,而作为系统一方,他需要对不同时间戳,不同程序连接的Socket所传递的字符串都做出统一的管理,那么linux内部是如何管理这些字符串的呢?
我阅读了linux0.11的源码,他使用的是sk_buff结构体存储一个字符串的相应信息,并且通过双向链表来维护他。在下面我写了linux代码的关键部分。
1 | struct sk_buff { |
大抵结构如上所示,因此每收到一个socket的字符串,系统都会保存起来,而保存的方式就是建立一个缓冲区,分配相应的内存块,并且设立报文的头指针和尾指针。然后在添加相应报头信息的时候移动头指针和尾指针,来扩大缓冲区存储的区域。
这也是对socket连接传输信息过程中对Data Buffer的开销的具体解释,我们原本粗浅的理解为将字符串用户进程复制到内核进程的缓冲区,再通过相应的操作传出去。在阅读了相应的知识和源码后,应该就能理解为什么要这么做。os缓冲区的建立是为了进一步添加不同的层级协议报文,这也会不可避免地带来多余的开销。
也因此,Socket其实并不是一个协议,而是为了方便使用TCP或UDP而抽象出来的一层,是位于应用层和传输控制层之间的一组接口。
PS:项目中webrtc创建的stun/turn服务器原理
本次项目运用到了基于websocket协议的视频传输以及消息传输。
而所谓的websocket,webrtc,http,这些都是基于TCP/IP上层的进一步封装。
视频通讯基于webrtc,webrtc本质上是peer-to-peer的socket连接,传送相应的视频信息,stun服务器的作用是将获取该主机真实的ip地址。如果没有对应局域网自己的ip地址。而turn服务器的作用就是当两者无法进行p2p连接时,作为中继站的服务器。
再到计算机网络
……待更